
AI世界的“壳”与“核”之争,向来是口水与唾沫齐飞的战场。每当有本土模型发布,质疑总如影随形:“套壳”、“蒸馏”、“算力依赖”。这一次,风口浪尖上的智谱选择了最硬核的方式回应——掏出了厚厚一份GLM-5技术报告,把代码、算法、架构“摊开晒太阳”。
这不是一次常规的版本更新,而是智谱试图为行业定义一个新方向:从“氛围编程”的炫技,转向“智能体工程”的硬仗。简单说,过去的模型或许能帮你写几行漂亮的代码片段,而GLM-5的目标,是成为一个能自主规划、执行并完成整个复杂软件工程的“系统架构师”。

那么,支撑这次跃迁的技术底气是什么?报告指出了四大核心支柱:
第一,是“聪明地省钱”的注意力机制。GLM-5引入了一种名为DSA的稀疏注意力机制,可以动态判断哪些信息是关键,哪些可以“简略带过”。这项创新让其在保持强大长文本理解和深度推理能力的同时,大幅压低了训练和推理的算力成本,为将模型规模推至7440亿参数、并用28.5万亿Token训练奠定了基础。
第二,是一套让GPU“拼命干活”的异步基础设施。它实现了“生成”与“训练”的深度解耦,解决了以往拖慢智能体训练进度的同步瓶颈,让模型能从海量的自主探索中高效学习。
第三,是一套旨在提升“决策智慧”的新算法。GLM-5的异步Agent强化学习算法,让模型能在动态、复杂的任务环境中持续学习规划和自我纠错,这正是其能处理真实工程任务的核心。
第四,也是最受产业关注的一点:全面的国产算力原生适配。智谱宣布,GLM-5已从底层完成对华为昇腾、摩尔线程、海光、寒武纪、昆仑芯、天数智芯与燧原七大主流国产芯片平台的深度优化。报告坦言,硬件生态的异构性让高性能部署异常艰难,但最终成果是:单台国产算力节点的性能,已可媲美由两台国际主流GPU组成的集群,长序列处理成本更是降低了一半。
当然,所有的技术指标最终都需要市场的检验。真正让这次发布充满戏剧性的,是一个代号为“PonyAlpha”的“匿名实验”。智谱将GLM-5隐去所有品牌信息,悄然放在了全球开发者平台OpenRouter上。

这场“盲测”的结果,或许比任何榜单都更具说服力。开发者社区被这个“神秘高手”在处理复杂代码和长程Agent任务时的能力所震动,并开始疯狂猜测其身份。数据显示,25%的人猜它是国际顶级模型Claude Sonnet 5,20%猜是Grok的新版本,10%认为是另一国产强者DeepSeek-V4,而其余用户则准确猜中了GLM-5。
“当真相揭晓,它就是我们自己的GLM-5时,这对团队是极大的鼓舞。”智谱在报告中写道。这次实验无意中变成了一场技术实力的“压力测试”,它试图证明,剥离品牌光环与地缘偏见后,纯粹基于“好不好用”的判断,中国本土模型已经能够赢得全球开发者的严肃认可。
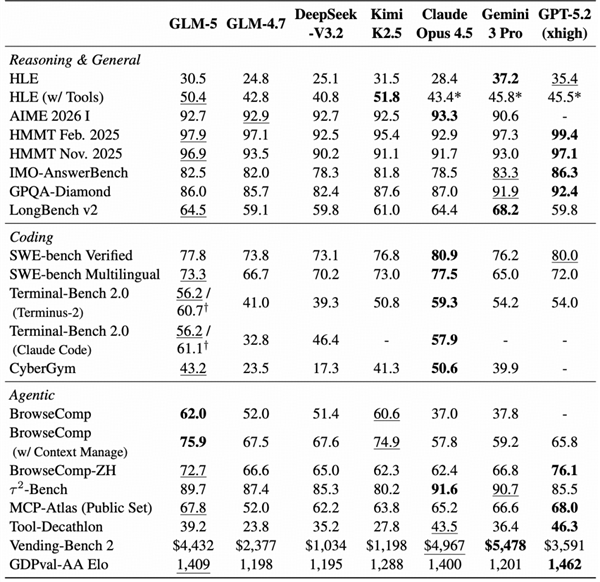
在硬性指标上,GLM-5同样表现抢眼。在ArtificialAnalysis综合榜单中位列全球第四、开源第一;在编程专项基准SWE-bench和TerminalBench 2.0中取得开源模型最高分,性能超过部分国际闭源模型。内部评估显示,其在复杂开发任务上的能力较前代平均提升超20%,使用体验逼近顶尖闭源模型。
报告结尾流露出一种“庆祝但清醒”的姿态。智谱承认,开源追赶闭源的战役远未结束,但GLM-5的发布清晰地传递了一个信号:中国AI的竞技场,正在从追逐“想象力”的惊艳瞬间,更深地扎进构建“工程可靠性”的硬核长跑。当模型开始真正接手系统工程,比拼的将不仅是灵光一现的代码,更是稳定、可控、高效的交付能力。这,或许是GLM-5揭开所有技术细节后,留给行业最有价值的启示。