



京东这波操作有点意思,他们悄咪咪开源了一个叫 JoyAI-VL-Interaction 的实时视频视觉语言交互模型——听起来很复杂?简单说,就是让AI从“你问它答”进化到“它边看边说”,而且是全球首个全栈开源的视觉交互模型加整套部署系统。
传统的图文视频大模型,基本就是个被动工具人,你得先问“这画面里有人摔倒了吗?”它才慢悠悠分析。京东这套模型上来就原生适配 vLLM-Omni,彻底打破这种尴尬——它能一直盯着实时画面,自主判断啥时候该主动开口,没大事就安静如鸡。
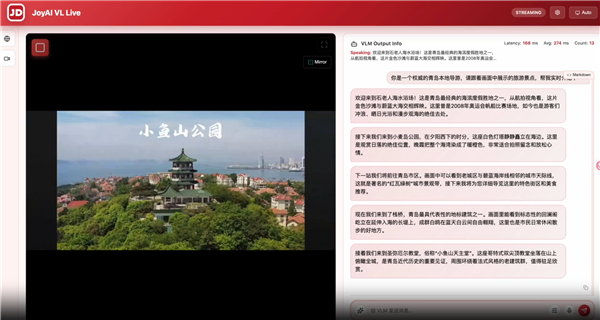
具体牛在哪?三个关键词:主动判断、低延迟流式处理、前台后台分工协作。能实时识别火情、老人摔倒这种突发事件并及时预警,不用等人按快门;遇到复杂推理或代码生成这种重活,它还能把任务甩给后台Agent,自己继续盯着画面,无缝衔接。
更难得的是开源诚意——不止给了模型权重,还有专属交互数据集、完整训练方案、全套可部署工程框架。语音模块、可视化界面、第三方Agent、业务接口都能灵活替换。支持摄像头、监控流、直播流多路输入,自带长期记忆和语音收发能力。


实测数据也够硬:在覆盖监控预警、实时计数、实时翻译、直播解说的58组真人盲测里,对比豆包视频交互助手总胜率77.6%,对比Gemini视频交互助手总胜率87.9%,安防预警场景更是100%全胜。
归根结底,这模型的底层逻辑变了:交互主动性长在模型骨头里,而不是靠外部触发硬凑。一旦解决“边看边说”这个痛点,居家看护、安防预警、直播解说、智能眼镜辅助这些场景,落地速度会比想象中快不少。