



库克“入职”小米、贾跃亭“回国”,这些不过是AI生图模型一夜之间制造的“新常态”。就在上周,OpenAI悄然升级了ChatGPT内的图像生成模块,版本号未明但被社区直接冠以“Images 2.0”。结果不到24小时,社交媒体便被真假难辨的“官方截图”刷屏——小米高管被迫深夜辟谣,西山居一则伪造的解散公告甚至震动了二级市场。
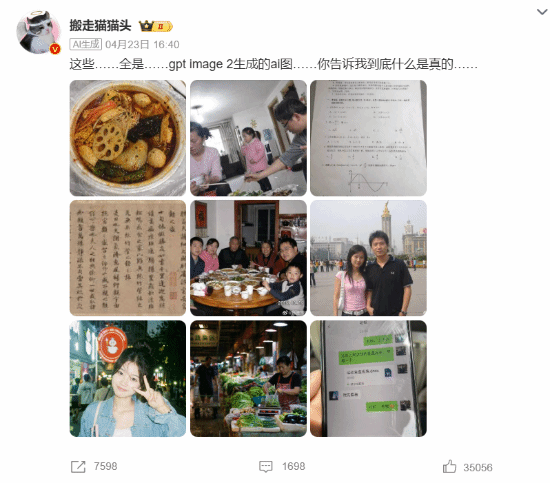


这场“视觉海啸”的可怕之处并不在于恶搞,而在于质感。传统AI生图常被诟病“一眼假”——手指畸形、文字乱码、光影别扭。但Images 2.0几乎填平了这条鸿沟:油渍反光的物理精度、直播评论区里带语气词的弹幕、工牌上的公司Logo和字体间距,统统做到了“肉眼0破绽”。




更难防范的是生成门槛。用户只需要一句口语化描述,模型就能在数秒内“拍”出一张带有精准中文字符、UI控件、甚至商业水印的截屏。这意味着任何人——没有Photoshop技能、没有美术基础——都能在几秒钟内伪造一份“企业红头文件”或“直播爆款截图”。




当造假成本趋近于零,伦理底线就被轻易踩碎。有用户借此做出“流浪汉闯入民宅”的报警级假图,引发整栋楼的恐慌;而“西山居解散”的AI伪造公告则因足够逼真,直接影响了相关公司的股价与舆论。资本市场对信息的信任体系,正在被一个文本提示词本身所动摇。
“以前我们默认截图是真的,现在这个底层假设崩塌了。”——这句评论成了当天转发量最高的声音之一。有网友悲观地表示,未来任何一张未经验证的图片都不该被当作“证据”,但我们显然还没有准备好一套新的验证机制。



从商业层面看,OpenAI这次放出的能力是一把双刃剑:它极大降低了内容创作的门槛,但同时也摧毁了“有图有真相”这个数字时代的底层信用基石。对于平台方、监管方和法律界来说,一个迫在眉睫的课题是——如何在保障技术创新的同时,搭建一套能够快速鉴别、追责、阻断恶意伪造的基础设施。否则,我们很快会进入一个比“后真相”更荒诞的时代:每张图都需要一个“非AI生成”的公证证书。