
阿里云今天抛出了一枚重磅技术炸弹——其通义千问团队正式发布了旗舰推理模型Qwen3-Max-Thinking。这不仅仅是又一个模型迭代,而是一次在核心推理能力上的系统性“升维”。多项国际权威基准测试结果显示,其综合性能已步入全球第一梯队,被业内视为目前最接近GPT-5.2、Gemini 3 Pro等国际顶尖水平的国产大模型。
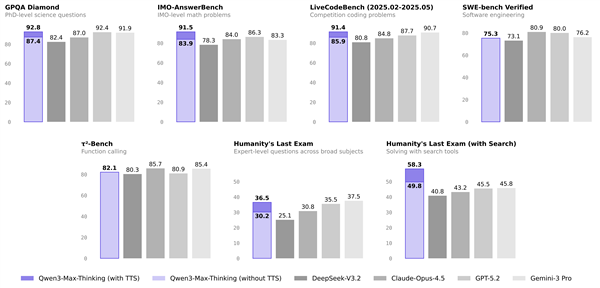
所谓的“性能飞跃”并非空谈。该模型在科学知识(GPQA Diamond)、数学推理(IMO-AnswerBench)、代码编程(LiveCodeBench)等硬核评测中,接连刷新全球纪录。其背后是超万亿(1T)的总参数规模和高达36T Token的预训练数据量构成的坚实底座。
更值得关注的是其背后的一项关键技术突破:测试时扩展(Test-time Scaling)机制。与业界常见的、可能导致冗余计算的“粗暴”增加推理路径不同,千问的新机制更像一个“经验萃取师”。它能对之前的推理过程进行提炼,并在此基础上进行多轮自我迭代优化,从而在消耗更少计算资源的同时,产出更智能、更精准的推理结果。
这项创新的直接收益体现在效率与性能的双重提升上。在被誉为“人类最后的测试”、允许使用工具的HLE基准中,Qwen3-Max-Thinking取得了58.3的高分,显著超越了GPT-5.2-Thinking(45.5分)和Gemini 3 Pro(45.8分),展示了其在复杂问题解决场景下的强大潜力。
面向未来“智能体(Agent)时代”的竞争,阿里此次也重点强化了模型的原生工具调用能力。Qwen3-Max-Thinking经过大规模、多任务场景的强化学习训练,能够更智能地结合搜索引擎、代码解释器等工具进行“思考”与决策。这意味着它不再只是一个被动回答的模型,而是一个能够主动调用资源、分步骤解决复杂问题的“数字助理”。目前,在QwenChat平台上,用户已能体验到模型自主调用搜索、记忆、代码解释三大核心工具的能力。
商业化落地方面,开发者现可通过QwenChat免费体验该模型,企业级用户则能通过阿里云百炼平台获取API服务。对于更广泛的普通用户,好消息是:千问App即将全面接入这个最强模型,并且对所有用户免费开放。这无疑将大幅降低公众体验顶级AI推理能力的门槛,也可能在国内AI应用市场掀起新的波澜。
从技术攻坚到平民化落地,阿里通义千问的这一步,不仅是在刷榜,更是在铺设一条从尖端技术到实际生产力的快车道。国内大模型竞赛的下半场,看来要进入“推理深度”与“应用智能”并重的新阶段了。