

OpenAI开源大模型实测:无需订阅、断网也能跑的ChatGPT平替方案
8月5日,OpenAI时隔多年首次发布开源大模型gpt-oss-20b/gpt-oss-120b,让Mac用户能够离线运行类ChatGPT的AI工具。实测表明,搭载苹果芯片的Mac无需订阅服务或联网,就能实现高性能AI运算。
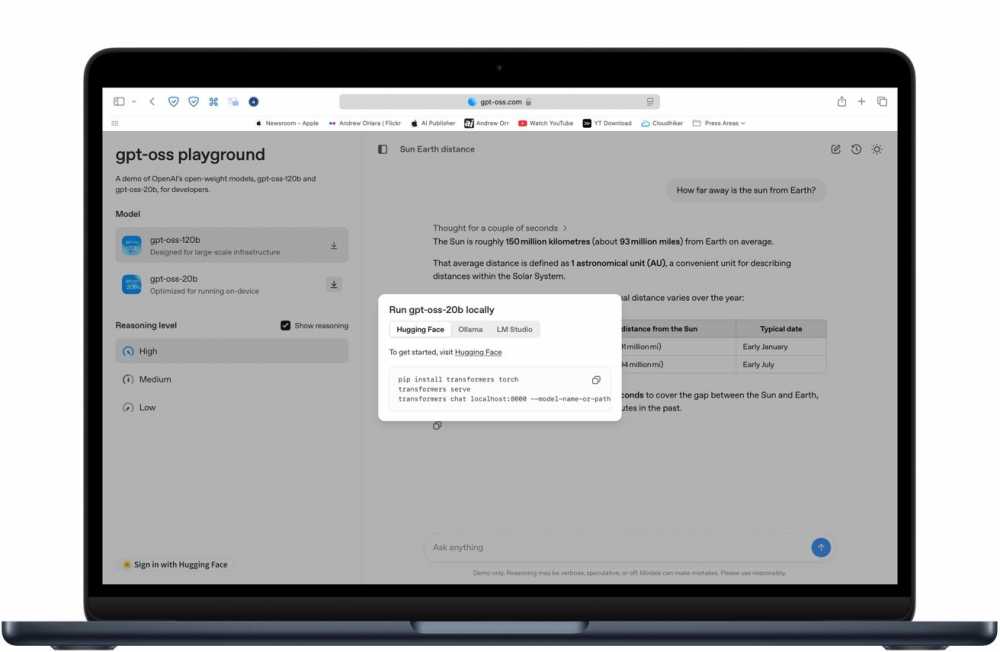
开源模型提供网页版试用入口
硬件需求分析
基本配置:建议至少搭载M2芯片+16GB内存,M1芯片需Pro/Max/Ultra版本。实测发现,使用M3芯片的MacBook Air运行时存在明显发热现象,性能表现与游戏场景类似——能跑但负载较高。
值得关注的是,苹果Mac Studio凭借卓越的散热设计成为最佳选择。这反映出本地AI运算与传统GPU密集型任务相似的特征:处理器性能、内存带宽和散热系统缺一不可。
工具链选择
- LM Studio:可视化操作界面,适合新手
- Ollama:命令行工具,支持模型管理
- MLX:苹果官方机器学习加速框架
Ollama实战教程
- 通过官网下载安装Ollama
- 终端执行
ollama run gpt-oss-20b命令 - 自动下载约12GB的4位量化模型
- 本地终端即可开始对话
实测显示,M3+16GB机型响应速度明显慢于云端GPT-4,但完整实现了离线对话功能。这种时延差异主要源于本地硬件算力限制与云端分布式计算的差距。
性能白皮书
20B模型经过4位量化处理后,可在16GB内存设备上稳定运行:(1)文本创作(2)知识问答(3)代码调试(4)函数调用
120B版本则需要60-80GB内存,更适合工作站场景。这种阶梯式设计既保证了消费级设备的可用性,又为专业用户保留了升级空间。
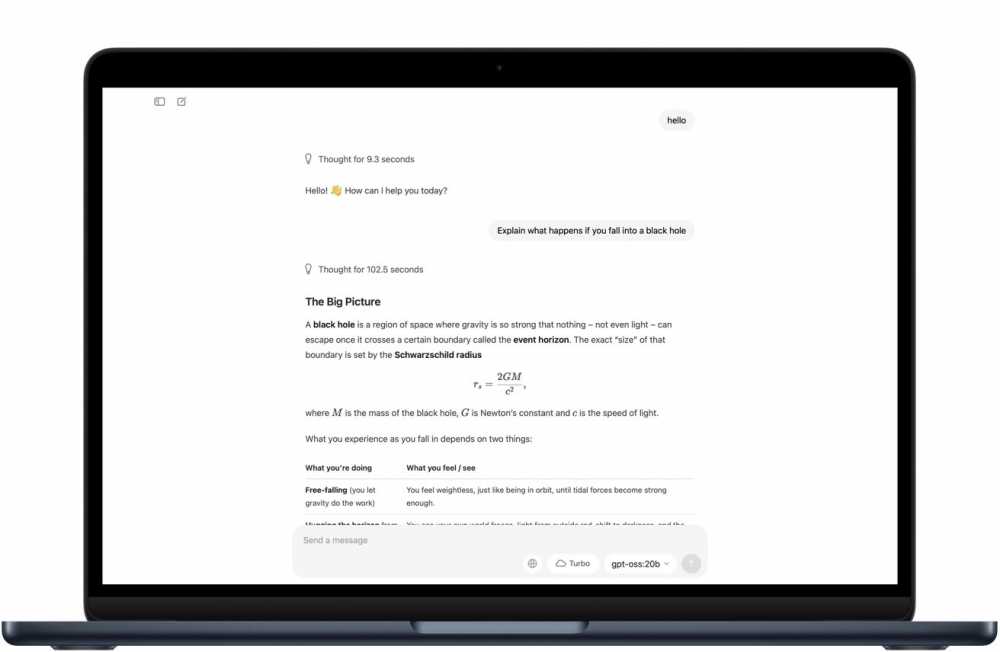
模型在专业领域存在认知边界
本地化价值
三重优势:(1)数据不出设备(2)免订阅费用(3)Apache 2.0协议允许微调。尤其值得关注的是模型支持MXFP4量化技术,这种4位浮点格式在保持精度的同时,将内存占用降低至原始模型的25%。
优化建议
低配设备建议:选用3B-7B参数的小模型,关闭后台应用,强制启用Metal加速。这种”减负增效”的策略,本质上是通过牺牲部分精度来换取可用性。
从技术演进角度看,本次开源释放了两个重要信号:首先是模型量化技术日趋成熟,其次是消费级设备已初步具备大模型部署能力。虽然现阶段还无法完全替代云端方案,但为AI私有化部署开辟了新路径。