
最近,一个据说是“探索健康应用”的“研究”被某公司披露了。具体内容呢,就是关于心率估算。这事儿听着挺高大上的,但仔细一分析,槽点可不少。
这个研究号称通过分析“心音图”(Phonocardiograms)来确定心率,而且还是用那些原本为语音识别设计的模型。这操作,怎么说呢?就好像你买了个高配游戏本,结果拿来当计算器用,不是不行,但总觉得哪里怪怪的。
研究里提到,他们测试了六个流行基础模型,包括那个大名鼎鼎的用于音频转录的“Whisper”。除此之外,还拉上了自家研发的“CLAP”(Contrastive Language-Audio Pretraining)模型。然后呢,这些模型不处理语音,去处理大约20小时的心音录音,这些录音来自一个名叫“CirCor DigiScope Phonocardiogram”的公开数据集。录音长度从5.1秒到64.5秒不等。听着数据量挺大,但实际效果如何,得看细节。
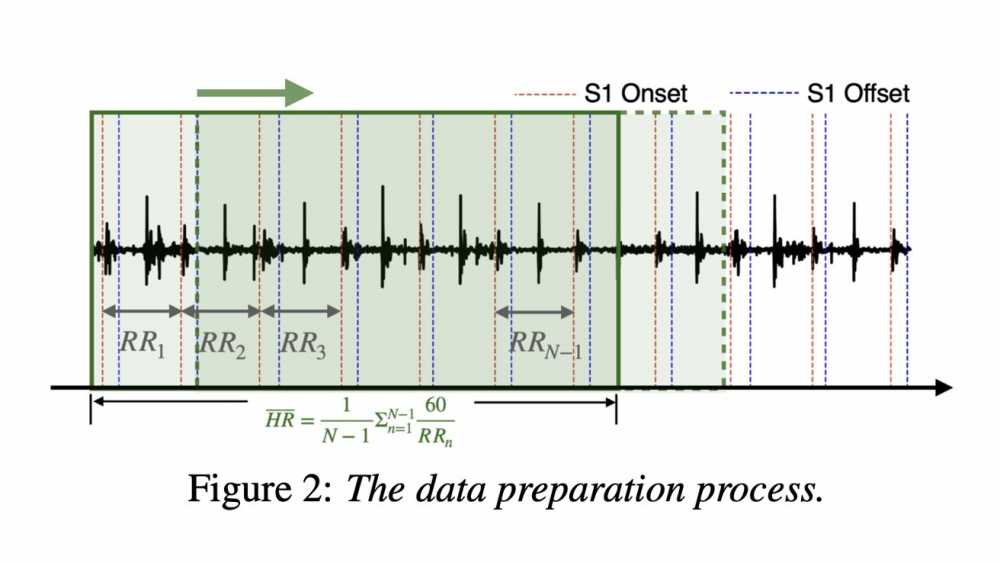
某公司号称对大约20小时的心音音频文件进行了测试。嗯,听起来很多,但细节决定成败。
人工标注了心音文件中的心脏杂音,然后把这些文件分成了每秒钟移动一次的五秒片段。最终得到了23,381个心音片段,目的是为了转换成心率测量数据。这操作,听着挺复杂,但说白了,就是把音频切碎了喂给AI。问题是,AI能真的理解这些“碎肉”代表什么吗?
研究报告里,他们得意地宣称自家CLAP模型比现有模型表现得更好。“我们观察到,内部CLAP模型的音频编码器在各种数据分割中实现了最低的平均绝对误差(MAE),优于使用标准声学特征训练的基线模型。”这话听着很漂亮,但仔细品味,这不就是“自家孩子永远最好”的标准套路吗?
他们还特意强调,不像Whisper、wav2vec2和wavLM这些主要基于语音训练的模型,他们家的CLAP模型是用包含非语音音频数据进行训练的。按他们的说法,这种多样化的训练数据“可能增强了其捕捉与心音相关的非语音特征的能力,从而提高了其有效性”。这逻辑听起来没毛病,但这不也侧面说明,专门针对心音数据进行优化的模型,效果肯定会比通用语音模型好吗?这还需要研究才能发现?这不是常识吗?
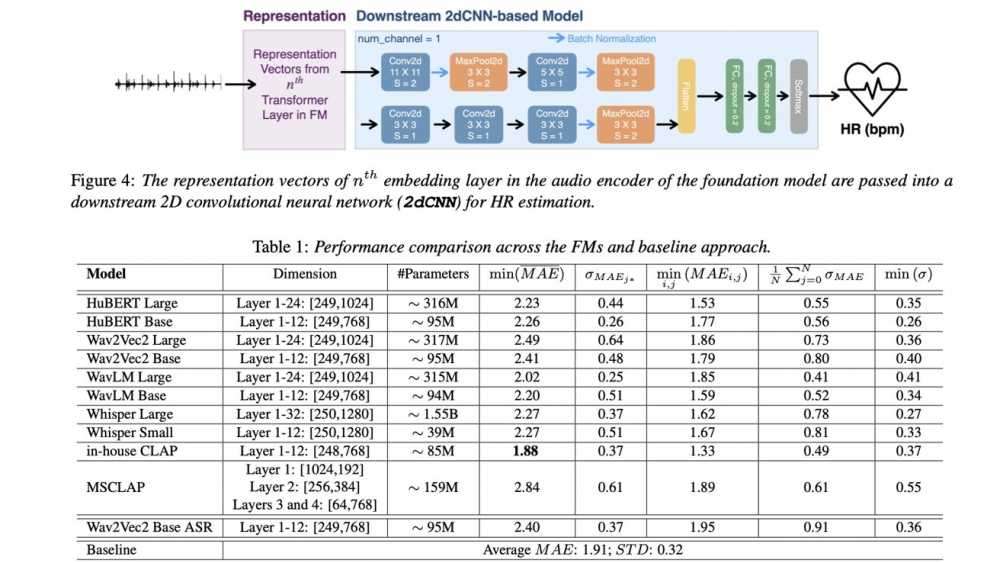
某公司宣称其内部CLAP模型“超越”了其他基础模型。嗯,自家模型赢了,意料之中。
研究人员煞有介事地说,为语音处理创建的基础模型“可以有效地适应听诊和生命体征估计,为某些传统方法提供了一个强大而高效的替代方案”。更玄乎的是,他们还说研究结果表明,更大的基础模型在确定心率方面并不总是表现更好。这不就是说,AI不是越大越好,而是要看“对症下药”吗?这种“发现”,真的值得大书特书吗?
报告还提到,对基础模型进行额外的微调可能会带来更好的心率估计。废话,任何模型不都是越调越好吗?不微调,你还指望它自己成精啊?他们还看到了这项技术在“心肺音病理分析”中的潜在应用,这“可能有助于更准确地检测心律失常和杂音等异常”。话是这么说,但从“可能”到“能”,中间的距离可不小。
至于这项技术将来会在设备上怎么应用,他们暗示可能会将其整合到未来的AirPods型号中。考虑到AirPods Pro 2已经支持了一系列听力健康功能,这似乎是顺理成章的。话说,2024年12月就传出某公司要给AirPods加入心率和体温传感器,现在又说要用现有麦克风配合新传感器来更准确测心率。这难道不是在给未来的AirPods新功能预热吗?说白了,这不就是一种营销手段,提前给消费者画个大饼,让大家期待一下未来的“黑科技”?至于落地效果如何,咱们还是等真产品出来再说吧。
总而言之,这个所谓的“研究”看似新颖,实则不过是把现有技术做了个包装,再掺杂一些看似高深实则常识的“发现”。与其说它是在探索健康应用,不如说是在为未来的产品做宣传,或者给投资者讲一个“科技改变生活”的故事。毕竟,在真金白银面前,所有的“研究”都显得那么“恰到好处”不是吗?