
【2025-03-25 20:01:00AI Siri网最新消息】
A PowerBook G4 running a TinyStories 110M Llama2 LLM inference — Image credit: Andrew Rossignol/TheResistorNetwork
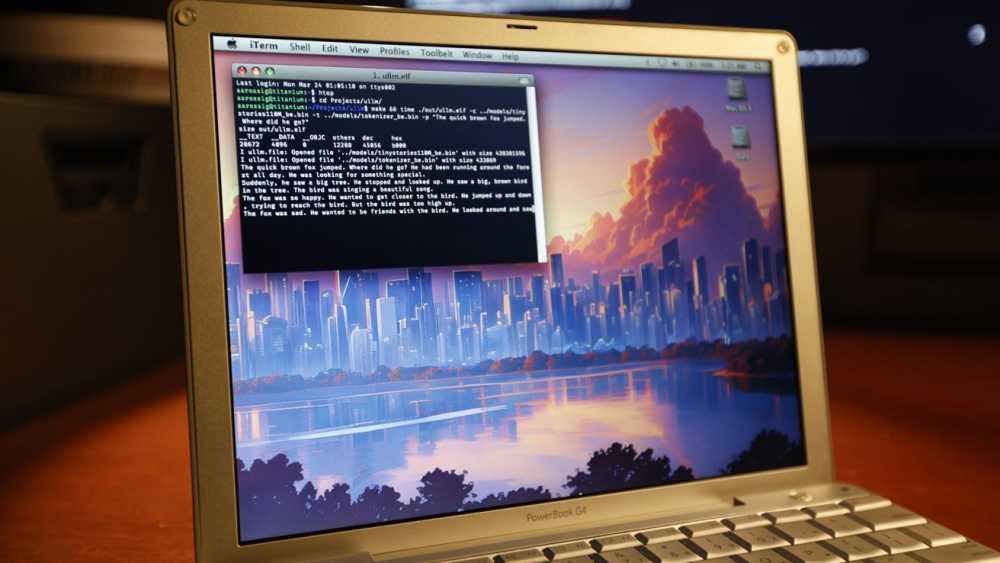
一位软件开发者证明了在2005年的PowerBook G4这样的老旧硬件上运行现代LLM(大型语言模型)是可行的,尽管速度远低于消费者的期望。
大多数人工智能项目,例如Apple Intelligence的不断推进,都依赖于拥有足够强大的设备来在本地处理查询。 这意味着更新的计算机和处理器,例如iPhone 16系列中最新的A系列芯片,由于具有足够的性能,通常用于AI应用。
在研究了llama2.c项目后,Rossignol使用单个C文件和没有加速器实现Llama2 LLM推理,并改进了该项目的核心。
这些改进包括系统函数封装、将代码组织成具有公共API的库,并最终将项目移植到PowerPC Mac上运行。 后者涉及“大端”处理器的问题,模型检查点和tokenizer期望使用“小端”处理器,指的是字节顺序系统。
速度并不快
llama2.c项目的建议是使用TinyStories模型,该模型用于最大化在没有专用硬件加速(如现代GPU)的情况下获得输出的机会。 测试主要使用模型的1500万参数(15M)变体完成,然后切换到1.1亿参数(110M)版本,因为更高的参数对于地址空间来说太大了。
模型中使用的参数数量会导致模型更加复杂,因此目标是在不牺牲响应速度的前提下,尽可能多地使用参数,以便生成准确的响应。 鉴于该项目的严格限制,这只能选择足够小的模型才能使用。
为了比较PowerBook G4项目的性能,将其与单个主频为3.2GHz的Intel Xeon Silver 4216核心进行了对比。 基准测试得出,查询的测试时间为26.5秒,每秒6.91个token。
在PowerBook G4上运行相同的代码是可行的,但速度要慢得多,需要4分钟,比单个Xeon核心慢9倍。 通过更多的优化,包括使用像AltiVec这样的向量扩展,推理操作缩短了半分钟,或者说PowerBook G4仍然慢8倍。
研究发现,所选模型能够生成“异想天开的儿童故事”。 这有助于缓解调试过程中的沉闷气氛。
超越速度
由于32位和最大可寻址内存为4GB等限制,测试硬件似乎不太可能获得更多性能提升。 虽然量化可能有所帮助,但可用的地址空间太小。
Rossignol承认该项目目前可能就此止步,但他表示该项目“是让我初步了解LLM及其工作方式的好方法。”
他还补充说“一台比[Xeon]年轻15年的计算机能够做到这一点,这相当令人印象深刻。” 这反映出软件开发领域的技术更新迭代速度之快,以及硬件设计上的巨大进步。
这个在旧硬件上运行现代LLM的演示,让用户看到了他们的旧硬件可以从退休中被带出来并仍然可以与AI一起使用的希望。 但是,请记住,前沿的软件开发运行会受到限制,并且速度比现代硬件慢得多。
除非发现能够最大程度地减少处理需求的极端优化方法,否则总体而言,那些从事LLM和AI工作的人员仍然需要购买更现代的硬件来完成任务。
最新的M3 Ultra Mac Studio是一种运行大型LLM的好方法(如果极其昂贵的话)。 但是对于涉足该主题的业余爱好者来说,修补PowerBook G4之类的项目仍然是有意义的。 尽管性能差距巨大,但该项目展示了在资源受限环境中进行创新的可能性。